A World Model That Knows What It Doesn't Know
All the models I had built so far for spatial reasoning maintained a single, definitive picture of the world. At any moment, the model's internal state was a fixed set of numbers representing "this is where things are." No hedging, no uncertainty.
But spatial understanding is inherently uncertain. You saw a cup on the counter three steps ago, but you've turned away since then. Is it still there? Probably. You're pretty sure. But you're not certain. A model that stores "cup is at (2.1, 0.8)" as a hard fact, versus one that stores "cup is probably near (2.1, 0.8) but I'm less sure because I haven't seen it recently," should behave differently.
This article covers the model that ended up working best across all twelve experiments I ran.
The idea: maintain a distribution, not a point
Instead of each memory slot storing a single feature vector (the model's best guess about the world), each slot stores a distribution: a mean (the best guess) and a variance (how uncertain that guess is). The mean says "I think the cup is here." The variance says "and I'm this confident about it."
The update rule follows a simple logic:
When the agent moves (no new observation): the mean shifts to account for the movement, and the variance grows. Uncertainty increases when you're not looking. This is the predict step.
When the agent sees something new: the mean shifts toward the observation, and the variance shrinks. Uncertainty decreases when you get evidence. This is the correct step.
This is the same logic as a Kalman filter, but learned end-to-end from data instead of hand-designed. The model learns when and how much to widen uncertainty, and when and how much to narrow it.
First test: toy world
I tested this against the persistent state model (the strongest deterministic baseline from the memory architecture experiments) on the same procedural 3D world with colored shapes.
The belief model won on 4 of 5 evaluation splits. The biggest gains were on counterfactual reasoning (+6.7 points) and relation queries (+8.4 on the hardest split). The model was correctly calibrated on in-distribution data: it reported higher uncertainty when it got the answer wrong than when it got it right.
Good sign. But toy data is toy data.
Moving to real 3D environments
The toy world (random colored shapes in a box) had served its purpose for fast iteration. To know if this actually works, I needed real rooms with real objects.
I used AI2-THOR, a 3D simulator with 120 realistic indoor scenes: kitchens, living rooms, bedrooms, and bathrooms. Each room has 50-90 objects (furniture, appliances, utensils) with proper physics, occlusion, and collision.
The data pipeline was the same format: the agent walks around, a pretrained DINOv2 vision model encodes each 256x256 frame into a 384-dimensional feature vector, and the model answers spatial questions about the world.
Small-scale real test: the belief model wins everywhere
With 313 training episodes (kitchens only), I compared persistent state vs belief model. The belief model won on all 5 evaluation splits, with margins larger than on the toy world (+7.7 on in-distribution vs +4.0 on toy). Real environments, with their complexity and ambiguity, actually amplified the benefit of tracking uncertainty.
Scaled test: the interesting pattern
Then I scaled to 1,500 training episodes across all 4 room types, with mixed trajectory lengths (10, 20, and 30 steps).
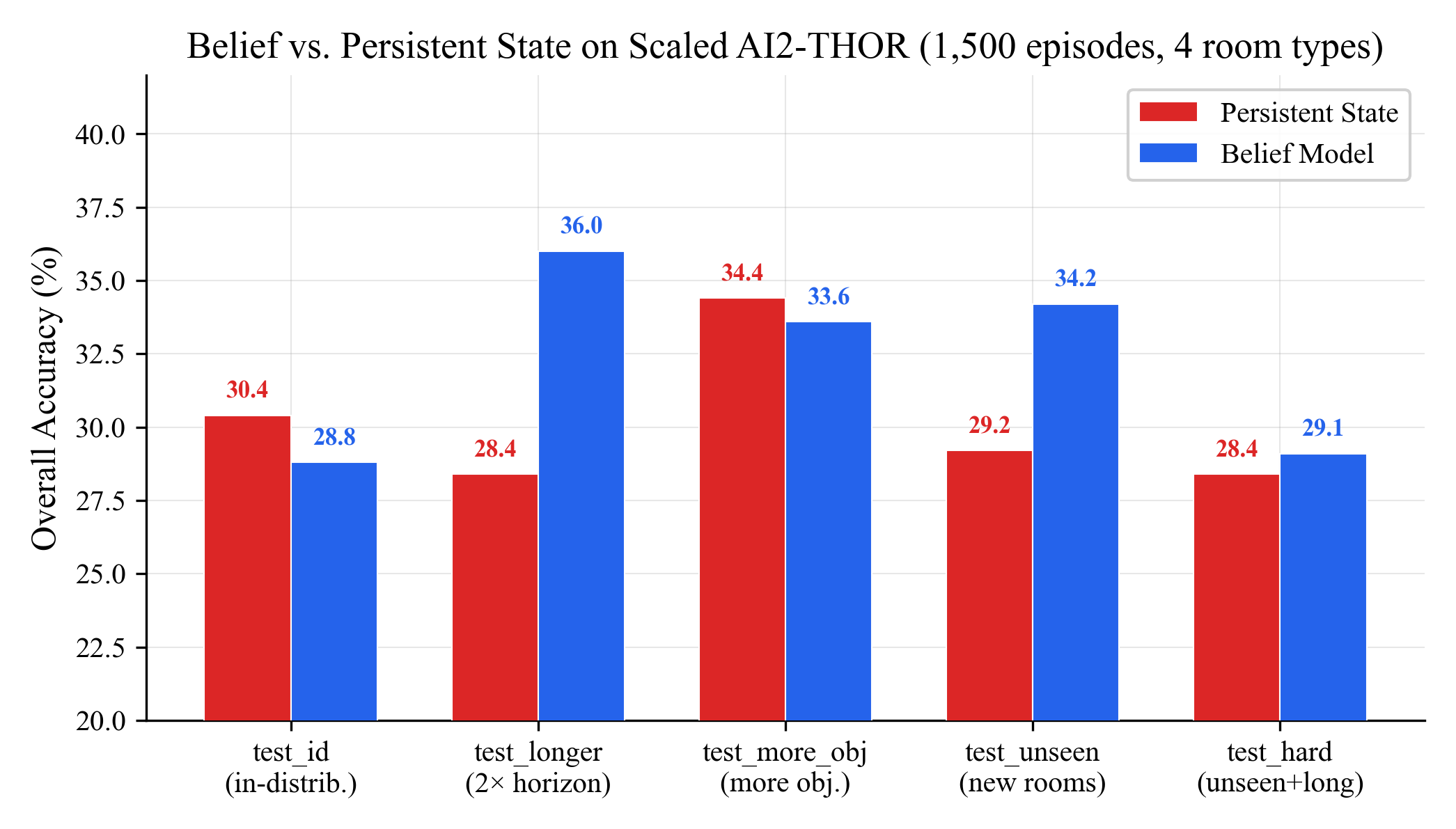
With more data, the deterministic model caught up on in-distribution performance (it actually wins by 1.6 points). But the belief model pulled further ahead on generalization: +7.6 on longer trajectories, +5.0 on unseen room types.
The story flipped compared to the toy world, and that's the most interesting finding:
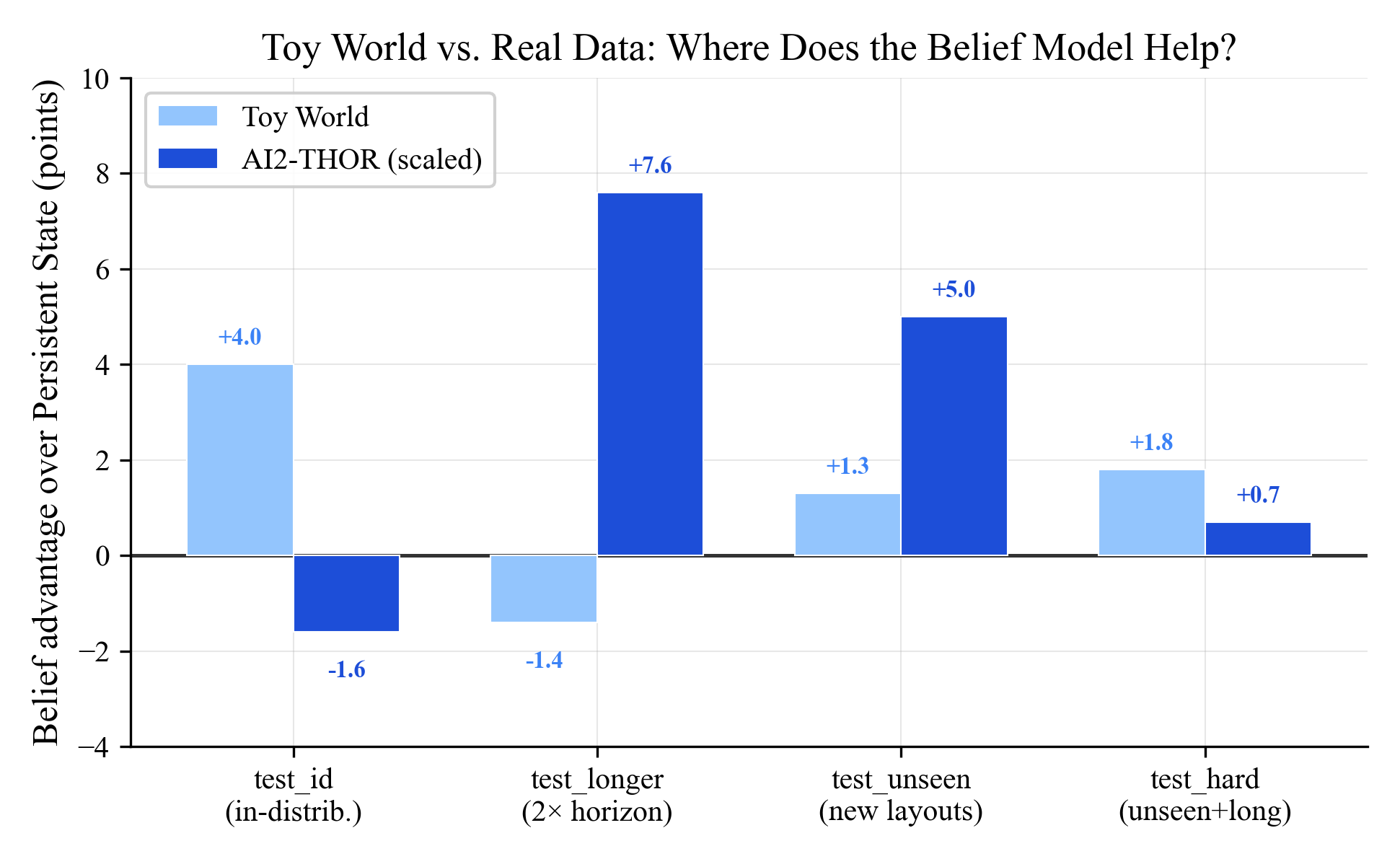
On toy data, belief wins in-distribution (+4.0) but loses on longer horizons (-1.4). On real data, the pattern reverses: belief loses in-distribution (-1.6) but wins decisively on generalization (+7.6, +5.0). The toy world was giving the wrong picture of where the belief model helps. The real-data result is what matters.
Where it wins by the most
The per-question-type breakdowns show where tracking uncertainty matters most.
On longer trajectories (2x the training horizon):
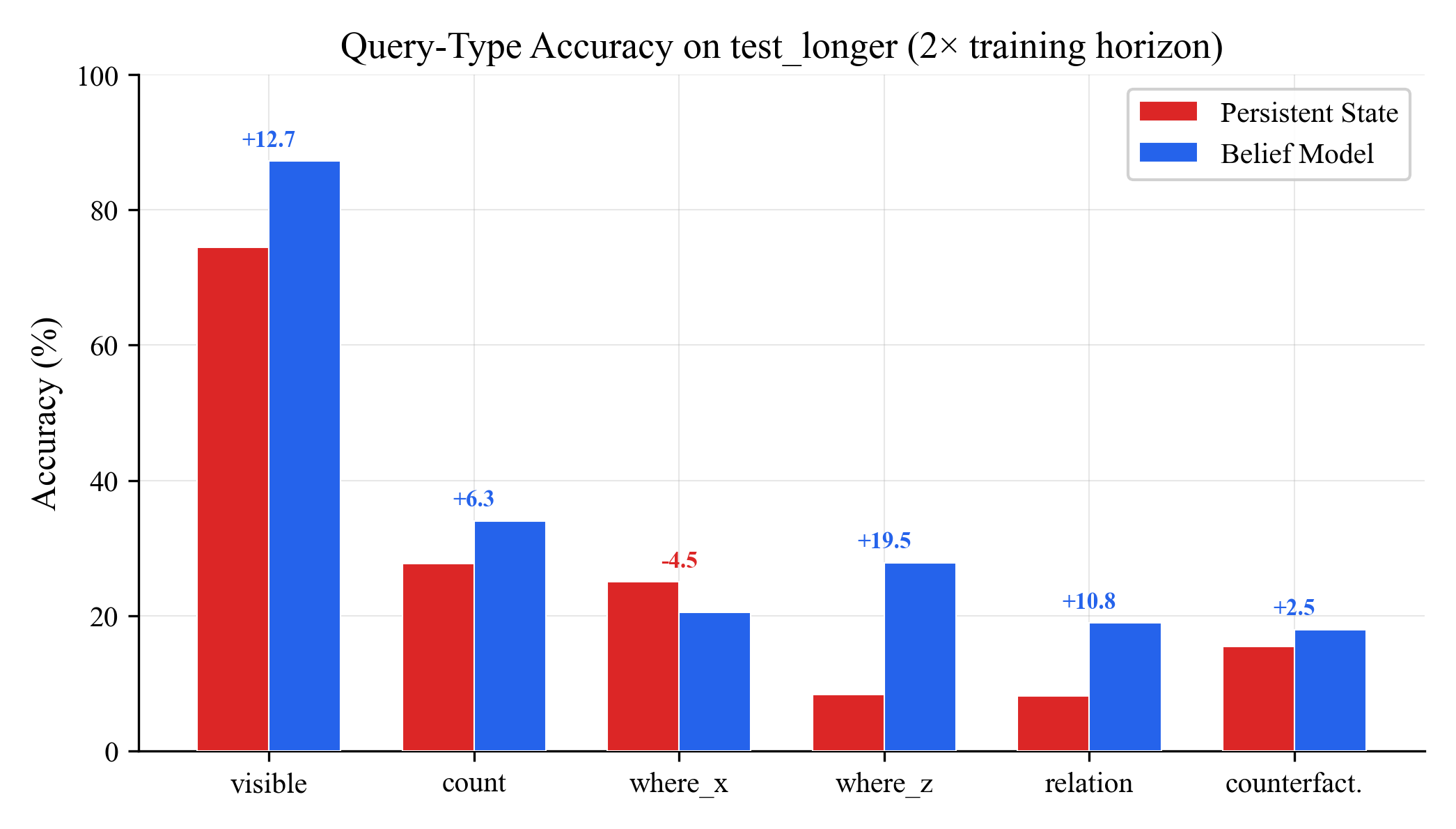
The belief model dominates on visibility (+12.7), coordinates (+19.5 on where_z), and relation queries (+10.8). These are exactly the questions where uncertainty matters: "is this object still visible after 60 steps?" requires tracking confidence about occluded objects. "Where is the object?" requires maintaining position estimates that degrade gracefully over time.
On unseen room types (bedrooms and bathrooms the model never trained on):
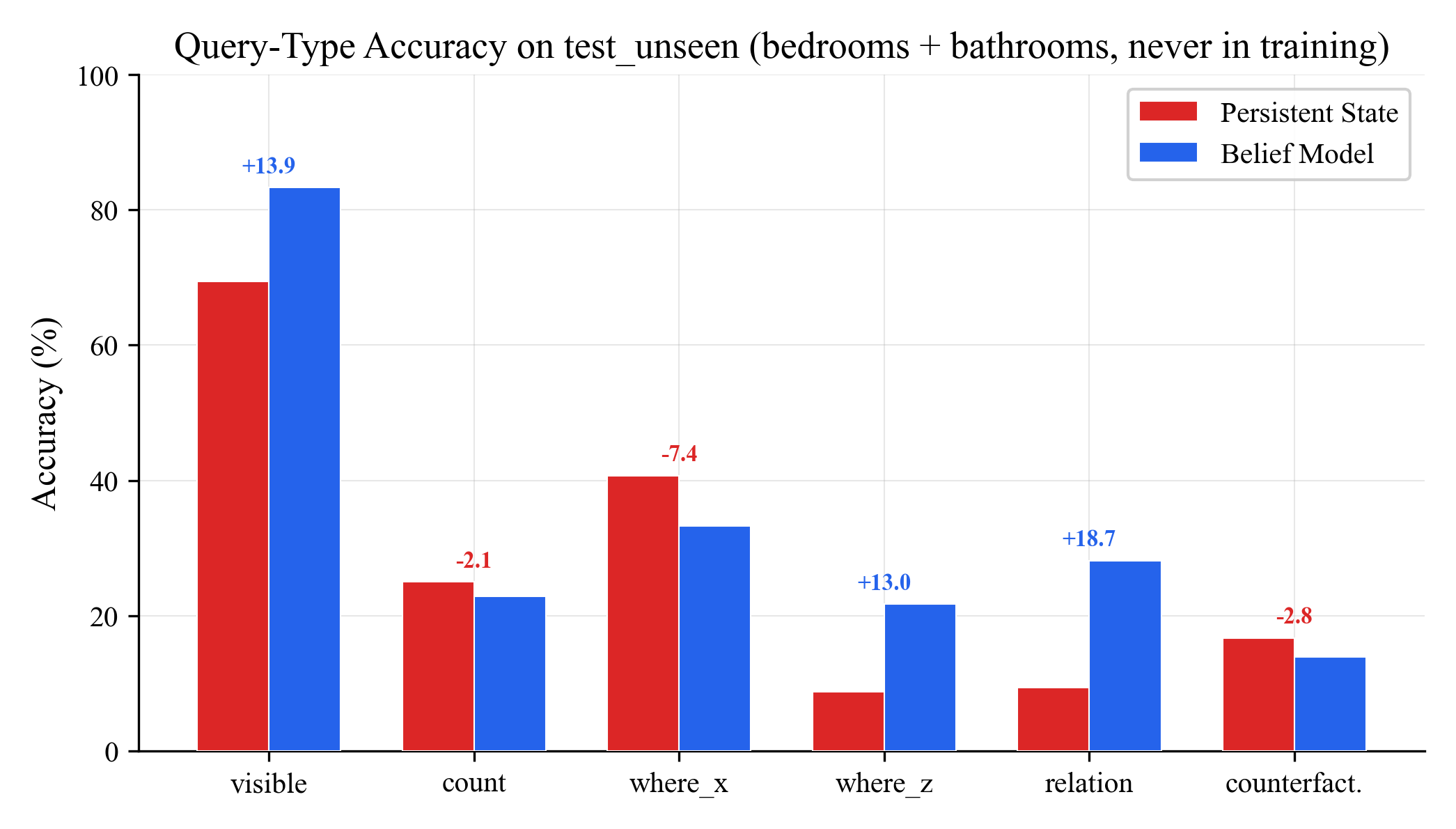
Same pattern. Relation queries show the biggest gap (+18.7 points). Visibility is +13.9. The belief model handles novel environments better because it knows that unfamiliar rooms should produce higher uncertainty.
Here's the detailed breakdown across all splits and query types:
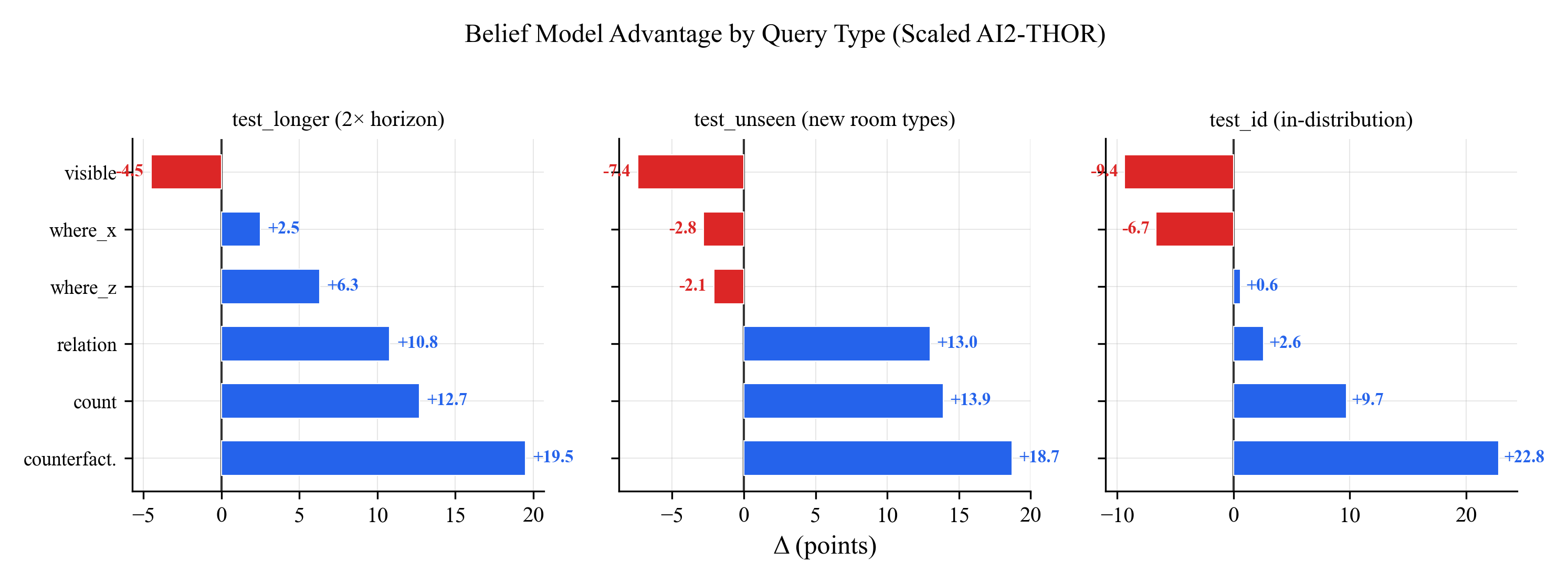
Blue bars point right (belief wins), red bars point left (persistent state wins). You can see at a glance: the belief model wins most query types on generalization splits, while persistent state only consistently wins on in-distribution coordinate queries where it has memorized the specific room layouts.
Counterfactual reasoning: the biggest single gap
Counterfactual questions ask "what if I had taken a different path?" This requires the model to maintain alternative possibilities, not just a single trajectory. The belief model's variance representation naturally supports this: uncertain beliefs about objects you haven't seen recently can accommodate multiple possible states.
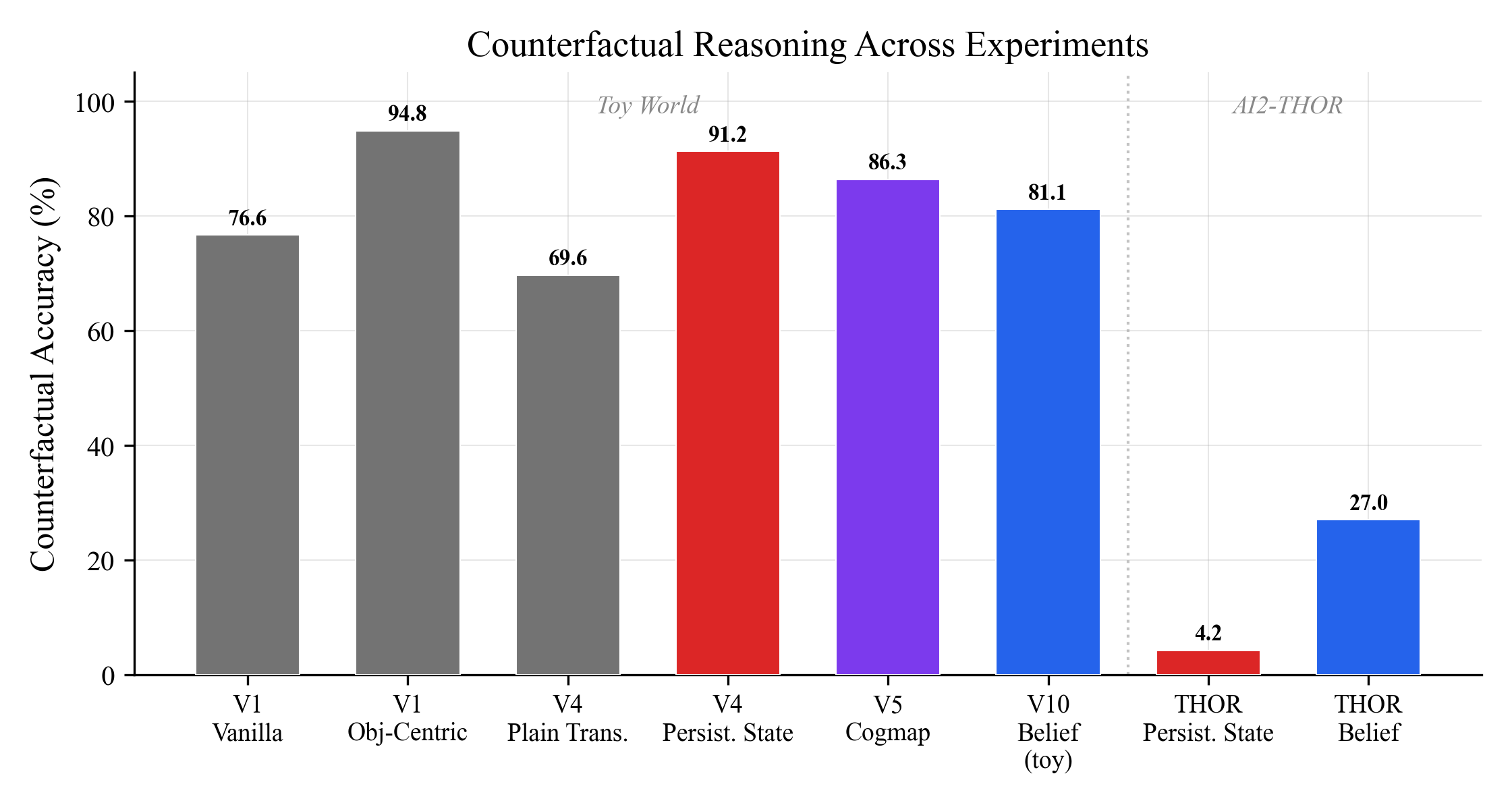
On toy data, all models handle counterfactuals reasonably (70-95%). On real AI2-THOR data, persistent state collapses to 4.2%. The belief model holds at 27.0%. That's a 22.8 point gap.
What this means
The belief model's predict-widen / correct-narrow dynamic captures something fundamental about spatial understanding. When you can't see something, uncertainty should grow. When you observe it, uncertainty should shrink. This sounds obvious, but encoding it as a learnable distribution over memory states produces measurably better generalization.
The deterministic model can memorize training rooms well enough to match or beat the belief model in-distribution. But the moment you test on longer horizons, unseen rooms, or counterfactual scenarios, it falls apart. The belief model's uncertainty tracking acts as a structural regularizer: it can't just memorize specific spatial configurations because it has to also model how confident it should be.
The practical recipe: if you're building a model that tracks state over time in a spatial setting, give it mean + variance per state variable and train it with a predict-then-correct update cycle. It's a small architectural change (24 slots x 2 for mean and variance = 3.6M params vs 2.9M for deterministic) with outsized impact on generalization.