What Kind of Memory Does a Spatial Reasoner Need?
If you want a model to navigate a room and answer questions about where things are, it needs some kind of memory. A standard transformer processes the full observation history as one long sequence. That works okay, but it has a problem: as the sequence gets longer, attention gets diluted. The model has a harder time pulling out the right information from 30 steps ago.
So I tried five different memory architectures, from simple to brain-inspired to self-organizing cellular grids. This is what I learned over two weeks and about a dozen experiments on 4x A100 GPUs.
The baseline: persistent state slots
The simplest idea that works. Give the model 24 learned "memory slots." At each time step, the model updates these slots by attending to the current observation (a visual frame encoded by DINOv2, plus the agent's position and action). The key detail: the update rule is conditioned on the agent's pose. The model knows where the agent moved, so it can update its memory accordingly.
This is the model I kept coming back to throughout the experiments. It's the baseline everything else was compared against.
The brain-inspired cognitive map (V5)
Inspired by how the brain separates place cells, grid cells, and object memory, I built a model with three explicit state components:
- Pose state (1 token) for tracking the agent's position
- Map state (8 tokens) for representing the room layout
- Object state (16 tokens) for tracking individual objects
The model used a predict, encode, correct update cycle (like a Kalman filter). First predict what the state should look like after moving, then observe the new frame, then correct the prediction based on what was actually seen. I also added self-supervised losses: the model had to predict the next visual observation from its current state.
It achieved the highest in-distribution accuracy (40.6% vs 37.3% for the plain transformer and 34.7% for persistent state). But it generalized worse than the simpler persistent state. The three-way state separation added overfitting surface without adding generalization power.
The self-supervised losses were genuinely useful though. Training the model to predict future observations improved spatial understanding even when measured on QA. The correction mechanism (comparing predicted vs actual) was effective. It was the explicit separation of pose/map/objects that hurt, not the predict-correct idea.
The spatial field (V6)
Instead of discrete memory slots, represent the world as a continuous 2D grid of features: 8x8 cells, each storing a 256-dimensional vector. The agent's observations update cells near its position, and the model reads from the full grid to answer questions.
This was interesting. It achieved competitive accuracy with half the parameters (1.4M vs 2.9M). Its big win was handling more objects: +5.7 points when tested on scenes with higher object density. The spatial grid naturally scales to more objects because adding objects just fills more cells, while discrete slots can run out.
But it degraded more on unseen room layouts. The fixed spatial grid is anchored to specific room scales and doesn't transfer well.
The self-organizing field (V7)
Make the field update purely local. Each cell only sees its 3x3 neighbors and updates via a single shared GRU (like a neural cellular automaton). The update is driven by prediction error: the cell predicts what it should contain, compares to what it actually sees, and adjusts where it was wrong.
Diagnostics confirmed this actually self-organized. Cells specialized (average cosine similarity between cells was only 0.175, far below the "everything is the same" threshold of ~0.8). Prediction error localized to specific cells. Some tracked dynamic content (objects), others tracked static structure (walls).
It won in-distribution (+1.6 pts) and on coordinate reasoning on hard splits (+8.6 pts), but lost on unseen layouts (-1.7 pts). Local-only dynamics can't propagate global information needed for understanding new room structures.
Adding global communication (V8, V9)
V8: I added 4 global tokens that read from and write to the entire field. Failed completely. All 4 tokens collapsed to identical representations (cosine similarity 0.9999). They became a single uniform broadcast bias.
V9: Fixed the collapse by giving each token a structurally different job. Token A reads only nearby cells, Token B reads the field mean, Token C reads only pose/action info, Token D reads aggregated prediction error. Collapse was fully solved (mean pairwise cosine = -0.032).
But even with proper specialization, the added complexity didn't clearly beat persistent state. It showed specific strengths (best generalization gap on longer sequences, 18% vs 9.3% on count queries) but at 2x the parameters and training instability.
What the full progression looks like
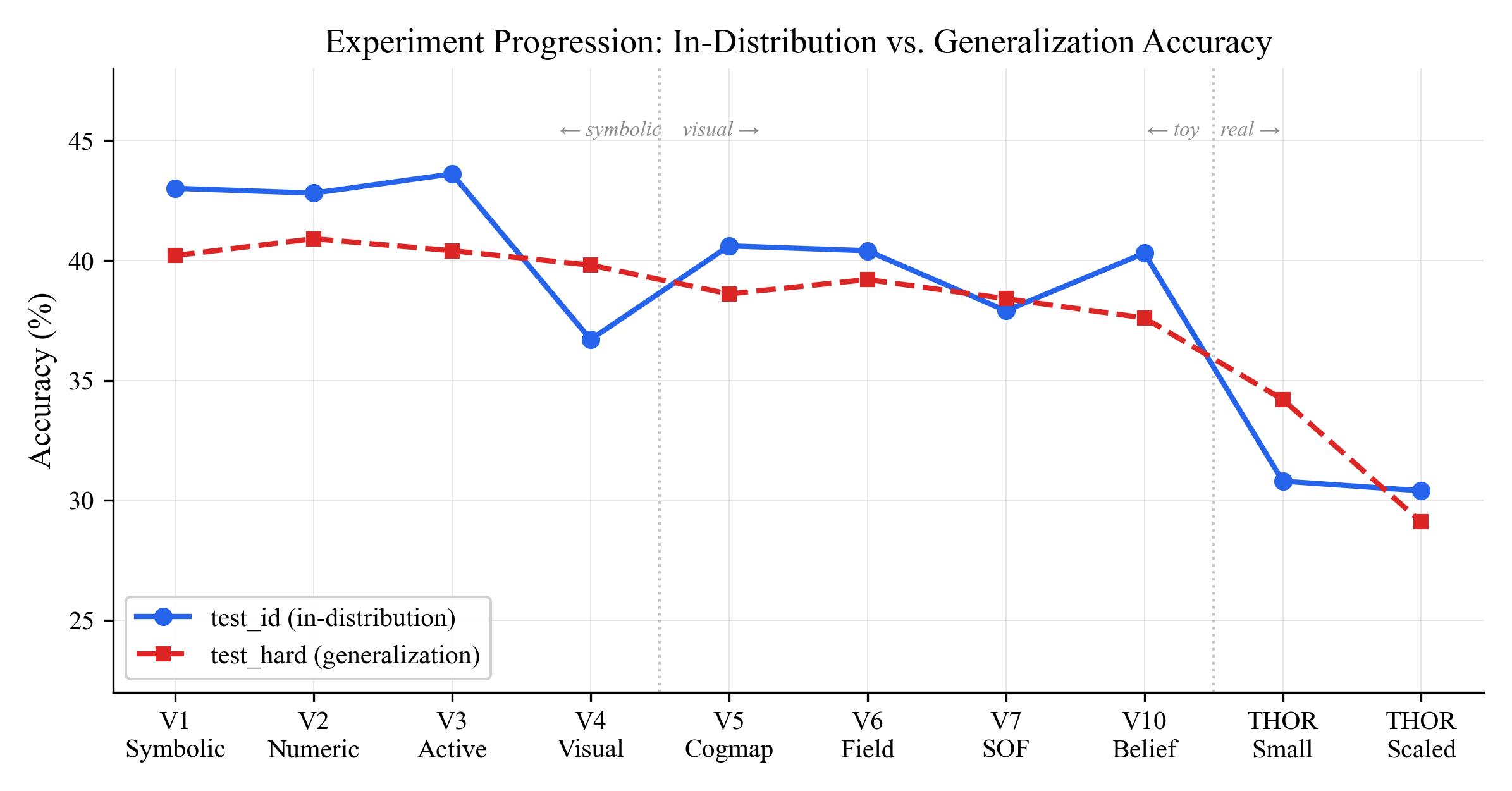
The solid line is in-distribution accuracy, the dashed line is the hardest generalization test (unseen rooms + longer trajectories). Two vertical lines mark the shift from symbolic to visual observations, and from toy world to real environments. Both lines drop when moving to harder setups, but the gap between them tells the generalization story.
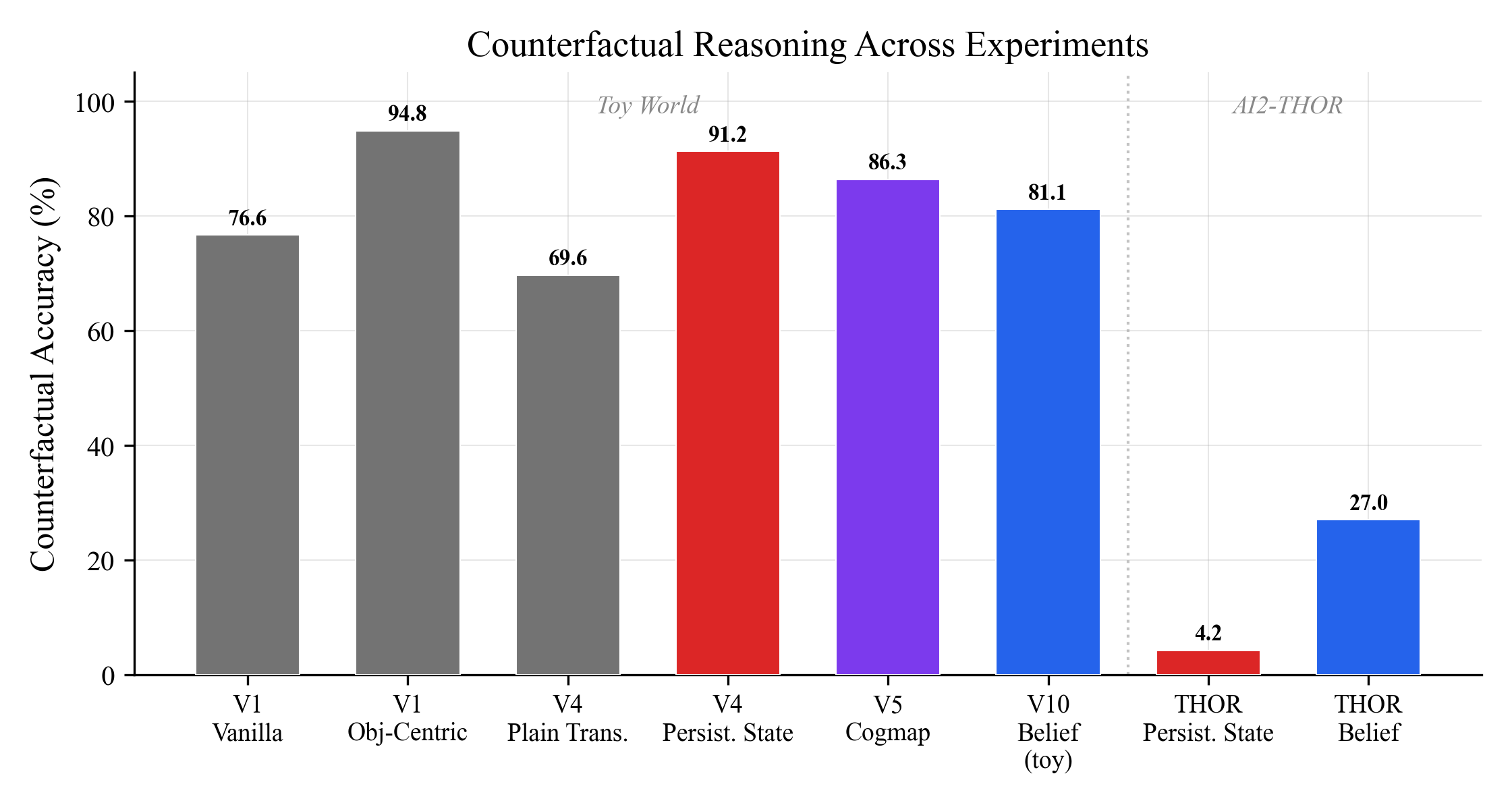
Counterfactual questions ("what if I had moved differently?") show the starkest pattern. In the toy world, models score 70-95% on counterfactuals. When moving to real environments (AI2-THOR), persistent state drops to 4.2%. The next article covers what fixed that.
What I took away
- Simple persistent state with pose-gated updates is a strong baseline. It's not the fanciest idea, but it's robust and generalizes well. The pose conditioning (letting the update rule know where the agent moved) was the critical ingredient.
- Brain-inspired separation of concerns overfits. Splitting state into pose/map/objects sounds principled but adds overfitting surface. Let the model figure out its own internal organization.
- Spatial grids scale better to more objects but transfer worse to new layouts. Discrete slots transfer better because they're not anchored to spatial coordinates.
- Self-organization works but local-only is not enough. Cells genuinely specialize when given local prediction error as a learning signal. But without global communication, the model can't reason about new room structures.
- Global tokens collapse unless structurally forced to be different. You can't just add capacity and expect diversity. You need to wire them to read from different sources.