Uncertainty-Guided Search Beats Beam Search
When a model solves a problem step by step, it sometimes makes a wrong choice at one of the steps. The question is: how do you catch and fix those mistakes?
How models normally handle multi-step problems
Imagine you're navigating a maze. At each junction, you pick a direction. If you always go with your first instinct, you'll sometimes hit dead ends. That's greedy decoding: the model picks its best guess at every step and never looks back.
The standard alternative is beam search. Instead of committing to one path, you keep several paths alive at once. At each junction, every active path branches into multiple options, and you keep the best-scoring ones. This explores more possibilities but costs more compute, since you're maintaining and evaluating multiple paths in parallel.
The problem with beam search is that it explores everywhere equally. It branches at easy junctions (where the model was probably right anyway) and hard junctions alike. Most of that branching is wasted compute.
The idea: only branch when unsure
What if the model could tell you which steps are hard and which are easy? At easy steps, just commit to the best guess (no branching, no extra cost). At hard steps, explore alternatives.
This is uncertainty-guided search. The model reports a confidence score at each step. High confidence means commit. Low confidence means branch.
Experiment 1: chained math operations
A small model predicts the result of applying operations (sine, square, inverse, etc.) one after another, up to 15 steps. The model isn't perfect. It makes mistakes. The question: does exploring alternatives help?
Here's what happened:
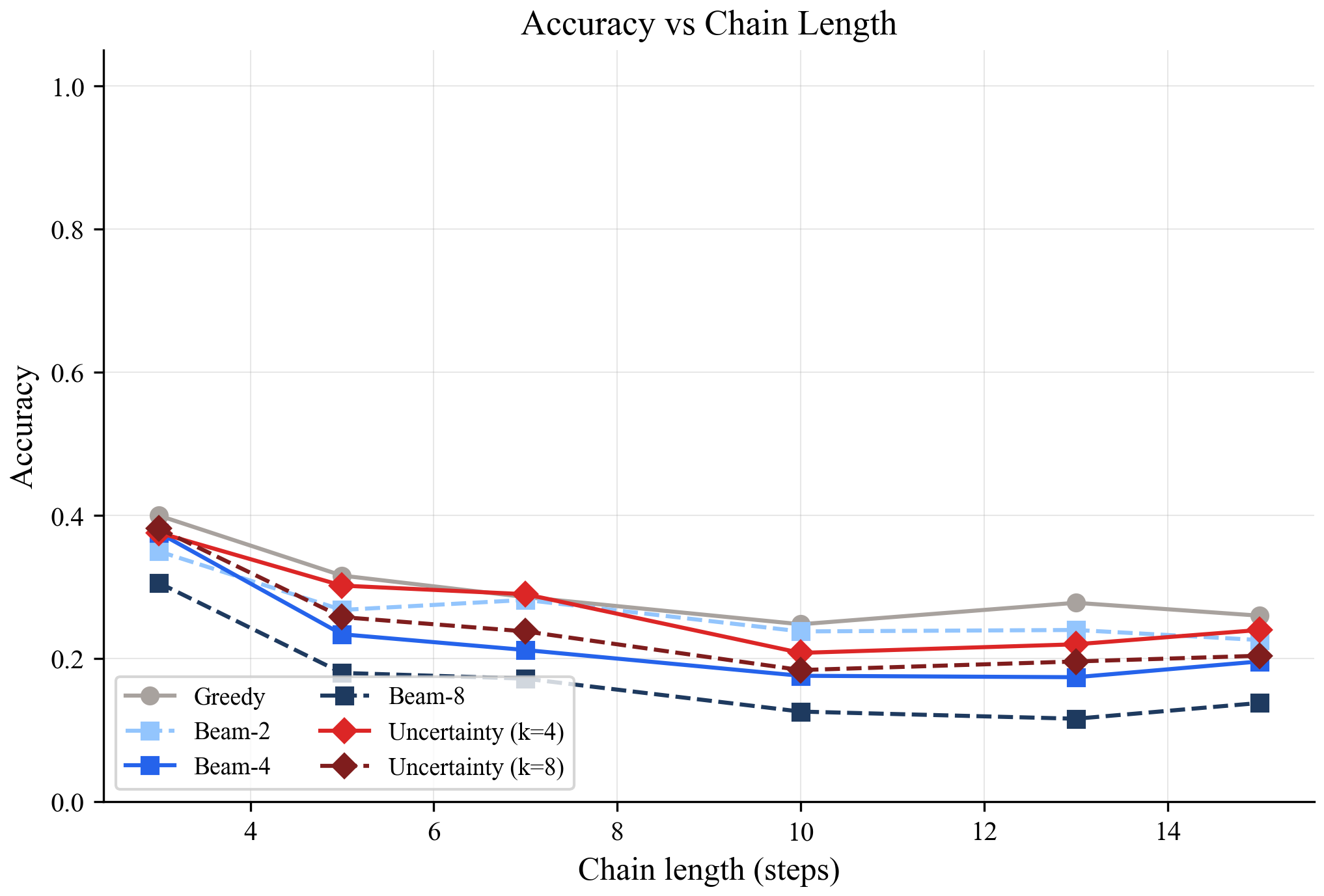
The gray line (greedy) is the best. The blue lines (beam search at different widths) get worse the wider the beam. Beam-8 is the worst performer at every chain length.
This was the surprise. Beam search made things worse, not better.
Why? At each step, beam search samples from the model's predicted range of values. Each sample is slightly different from the model's best guess. Those small differences are noise, and noise compounds across steps. After 15 steps of accumulated sampling noise, the beam search candidates have drifted further from the correct answer than greedy's single, clean prediction.
The red lines are uncertainty-guided search. It stays close to greedy (because it only branches on a few steps) but picks up a small advantage at uncertain steps where branching actually helps.
Here's the accuracy vs compute trade-off at different chain lengths:
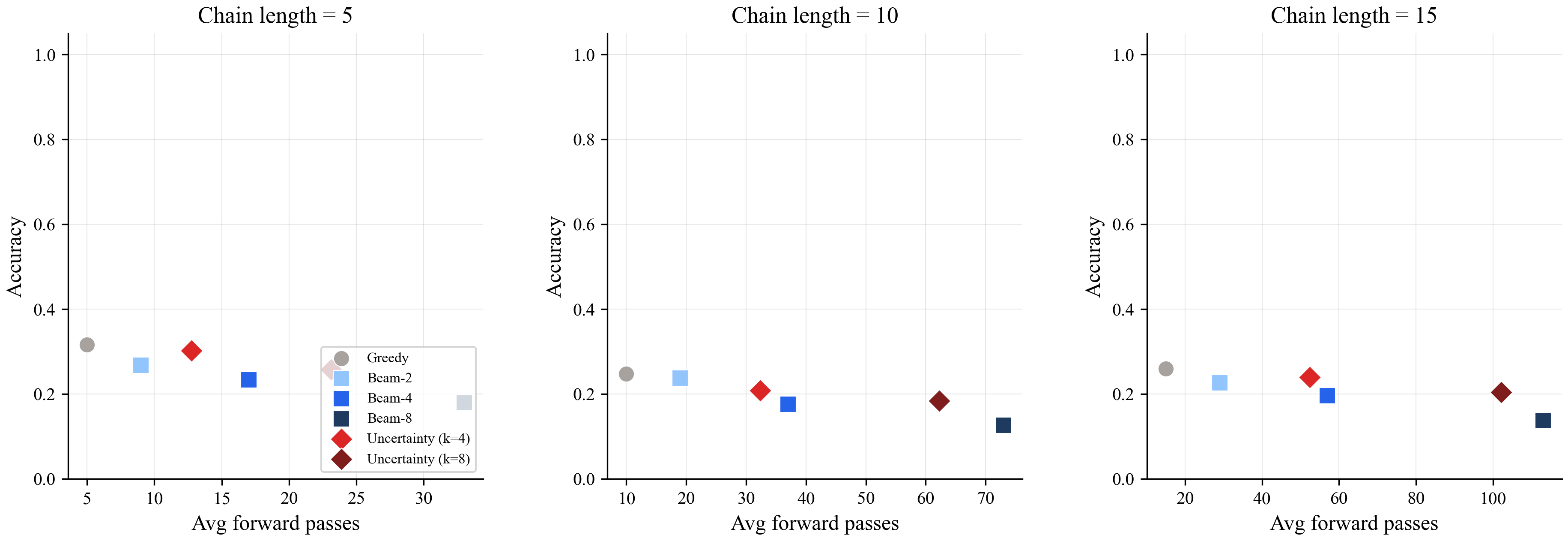
The best strategy is in the top-left corner: high accuracy, low compute. Greedy (gray circle) is there. Uncertainty-guided (red diamond) is right next to it. Beam search (blue squares) drifts toward the bottom-right: more compute, worse accuracy.
The model knows which steps are hard. Here's what its uncertainty looks like across a 10-step chain:
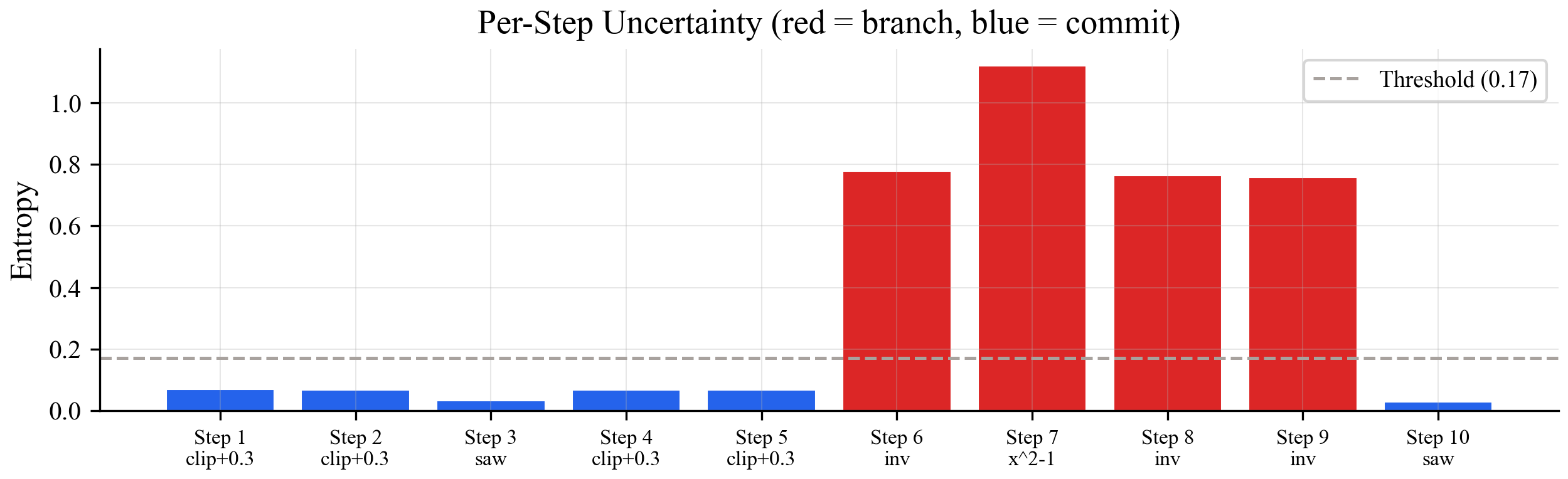
Blue bars are confident steps (clip, shift). Red bars are uncertain steps (inverse, x^2). The uncertainty-guided approach only branches at the red steps. Beam search branches everywhere.
Experiment 2: a real language model solving math
The continuous chain experiment was illustrative but artificial. For the real test, I used Qwen 2.5 (a 500-million-parameter language model) on arithmetic word problems like "Tom had 47 apples, got 31 more, gave away 11. How many does he have?"
The model solves these by generating text step by step. Sometimes it makes a mistake in the middle ("47 + 31 = 68" instead of 78) and the final answer is wrong.
Two ways to measure uncertainty at each step:
Token entropy: how spread out the model's predictions are for the next word. If it's split between "78" and "68", entropy is high. If it's sure about "78", entropy is low.
Latent density: how familiar the model's internal state looks compared to what its internal state looks like during correct reasoning. This uses a statistical model (a Gaussian Mixture Model) fit on the hidden states from examples where the model got the right answer.
Results on 50 test problems:
Greedy got 80% right. Both branching methods got 98%. They recovered almost every problem the greedy approach got wrong. And they did it with fewer total computation steps (65 vs 70), because catching the error early means the model finds the correct answer faster instead of generating more wrong tokens.
The two uncertainty measures (entropy and density) performed identically here. Simple arithmetic problems aren't complex enough to produce situations where the model is confidently wrong. For harder problems where the model's internal state is unfamiliar but its output looks confident, the latent density approach should catch errors that entropy misses. That's the next experiment to run.
What this means in practice
If you're running a model that solves problems step by step, don't use beam search blindly. On continuous predictions, it makes things worse. On language models, uncertainty-guided branching gets you beam search accuracy at greedy cost.
The model already knows where it's struggling. You just have to listen to it.
Code is in the uncertainty-driven-memory repo.