Training a 3D Fighting Game as a Neural Network
What if instead of coding a game engine with physics, rendering, and all the rest, you just showed a neural network thousands of frames of a game and it learned to generate new frames on its own? You press "forward" and the model draws what should happen next.
That's what this project is. I built a simple 3D robot fighting game, recorded a huge amount of gameplay data, and trained a neural network to act as the game engine. The input is a controller action (move, turn, punch). The output is the next video frame.
The game: Neon Sumo
First, I needed a game to learn from. I built Neon Sumo in the browser using Three.js (a 3D graphics library) and Rapier (a physics engine). Two animated robot models fight on a glowing hexagonal arena. They can move around, punch each other, and knock each other off the platform. Fall off and you respawn.
The game runs at 256x256 resolution with a fixed camera angle looking down at the arena. Two simple AIs control the robots, randomly switching between aggressive, wandering, and idle behaviors. The whole thing is deterministic given a random seed, so I could replay any match exactly.

Collecting the data
This is where the real engineering was. To teach a neural network what the game looks like, I needed to show it many thousands of frames. But not just the regular picture. For each frame, the game actually renders three different views:
RGB: the normal game frame, what a player would see.
Depth map: how far away each pixel is from the camera. Close objects are white, far objects are black. This gives the model a sense of 3D space.

Surface normals: which direction each surface is facing. This is color-coded (red = facing right, green = facing up, blue = facing toward the camera). It helps the model understand the geometry of the scene.

I ran 10 headless browser instances in parallel, each playing the game with a different random seed and streaming frames to a server. 24 hours of collection on a GCP VM.
Plus, for every frame, I recorded the 5-dimensional controller input: [forward, back, left, right, punch] as a simple yes/no for each button.
Compressing the data
256x256 images are too big to work with directly for a neural network that needs to process thousands of them. So I used Stable Diffusion's image encoder (VAE) to compress each frame from 256x256 pixels down to a compact 4x32x32 representation. Think of it as a very efficient summary of the image that keeps all the important visual information but in a much smaller package.
The depth and normal maps get downscaled to 32x32 and used as additional context. So for each training example, the model gets: the previous compressed frame, the current compressed frame (what it needs to predict), the depth + normals (for spatial awareness), and the action vector (what buttons were pressed).
The model: Diffusion Transformer
The actual neural network is a Diffusion Transformer (DiT) with about 100 million parameters. The way it works is:
- Start with random noise the same size as a compressed frame
- Gradually remove the noise over many small steps, guided by the previous frame and the action input
- What's left after removing all the noise is the predicted next frame
This is the same core technique behind image generators like DALL-E and Stable Diffusion, just applied to predicting game frames instead of generating images from text.
The action input (which buttons are pressed) is fed into the model by modulating the internal processing at every layer, so the model knows "the player pressed forward" throughout its entire computation, not just at the beginning.
Training ran on 4x L4 GPUs with mixed precision.
Training progress
The model starts by generating complete noise and gradually learns what the game looks like. Here's the loss curve showing the model improving over time:
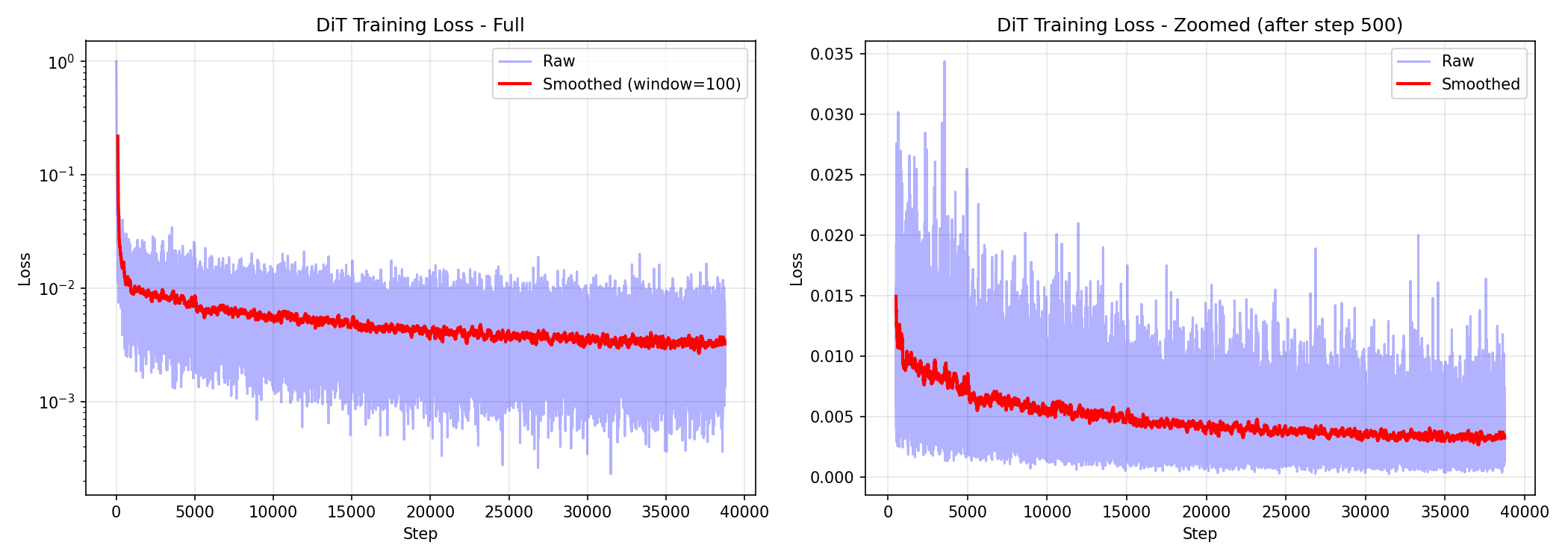
And here's what the model's output looks like at different points during training:
At 10,000 steps, it's just starting to learn that there's a hexagonal shape and some colored blobs:
By 30,000 steps, the arena shape, the neon grid pattern, and the robot silhouettes are clearly recognizable:

Playing the game through the model
The payoff: you can actually "play" the game through the neural network. Start with one real frame, feed in a sequence of button presses, and the model generates each next frame by taking its own previous output and the new action.
Here's a generated sequence of the two robots interacting on the arena:

Each generated frame feeds back in as input for the next one. The model responds to different actions differently: pressing forward moves the robot forward, punching triggers the punch animation. The arena stays stable and the 3D structure is maintained.
What worked and what didn't
The depth and normal conditioning made a big difference. Without them, the model struggled to keep the 3D structure of the arena consistent across frames. With them, it has geometric context that keeps the scene grounded.
The quality drifts over time. After about 30-40 generated frames, things start getting blurry and losing detail. This is the classic compounding error problem: each frame's tiny imperfections get fed into the next frame and accumulate. After enough frames, the errors pile up.
The robots are blobs, not detailed figures. Compressing 256x256 down to 32x32 loses a lot of fine detail. The robots are recognizable shapes with the right colors, but you can't see individual limbs or facial features. A higher-resolution approach would help.
It fundamentally works. A neural network can learn to "be" a simple 3D game. Given a frame and a button press, it generates a plausible next frame. The pipeline (data collection, compression, training, autoregressive generation) is solid and could scale to more complex games with more data and compute.
Code is at github.com/ali77sina/neon-sumo-world-model.