Your Model Can't Reason About Space Because It Can't Read Numbers
I was building models that navigate 3D rooms and answer spatial questions. "Where is the apple?" "Can you see the bottle from here?" "How many objects are visible?" The models were terrible at all of it. I tried three different architectures. None of them could answer coordinate questions above 2% accuracy.
Turns out the problem was embarrassingly simple.
The task
An agent walks through a 3D room full of objects. At each step it takes an action (move forward, turn left, turn right), sees a new view, and knows its position and heading. After 10-30 steps, it gets a spatial question about the world and has to answer it.
The questions test different things:
- "Where is object X?" requires remembering or inferring coordinates
- "What's the relation between X and Y?" requires understanding relative distances
- "Is X visible from here?" requires tracking what's in view vs hidden
- "How many objects can I see?" requires counting visible things
- "What if I had moved differently?" requires imagining an alternative path
Three architectures, same failure
I tried a vanilla transformer (process the full observation history as a sequence), an object-centric state model (maintain 32 learned memory slots updated at each step), and a geometric state model (same slots but with spatial consistency constraints baked in).
The state models were better overall. They beat the vanilla transformer by about 2.6 points and showed way better counterfactual reasoning (+18 points on hard test splits). So the state idea worked.
But all three models scored 0-2% on coordinate queries. Where is the object? No idea. What's the spatial relation? No clue. They couldn't learn any spatial geometry at all.
The diagnosis
The observations were text. The agent's position was the string "3.14" which the model tokenized as the characters "3", ".", "1", "4". Same for object coordinates, distances, everything spatial.
The model was trying to learn geometry from individual characters. It had to first figure out that "3", ".", "1", "4" together mean the number 3.14, and then learn spatial relationships between those numbers. That's an absurdly hard learning problem.
The fix
I replaced character-level text with numeric tensors. Each observation became a structured vector of floating-point numbers: agent state [x, y, z, cos(heading), sin(heading)], and for each object [id, shape, color, relative_x, relative_y, relative_z, distance, visible]. Just straight floats, no tokenization.
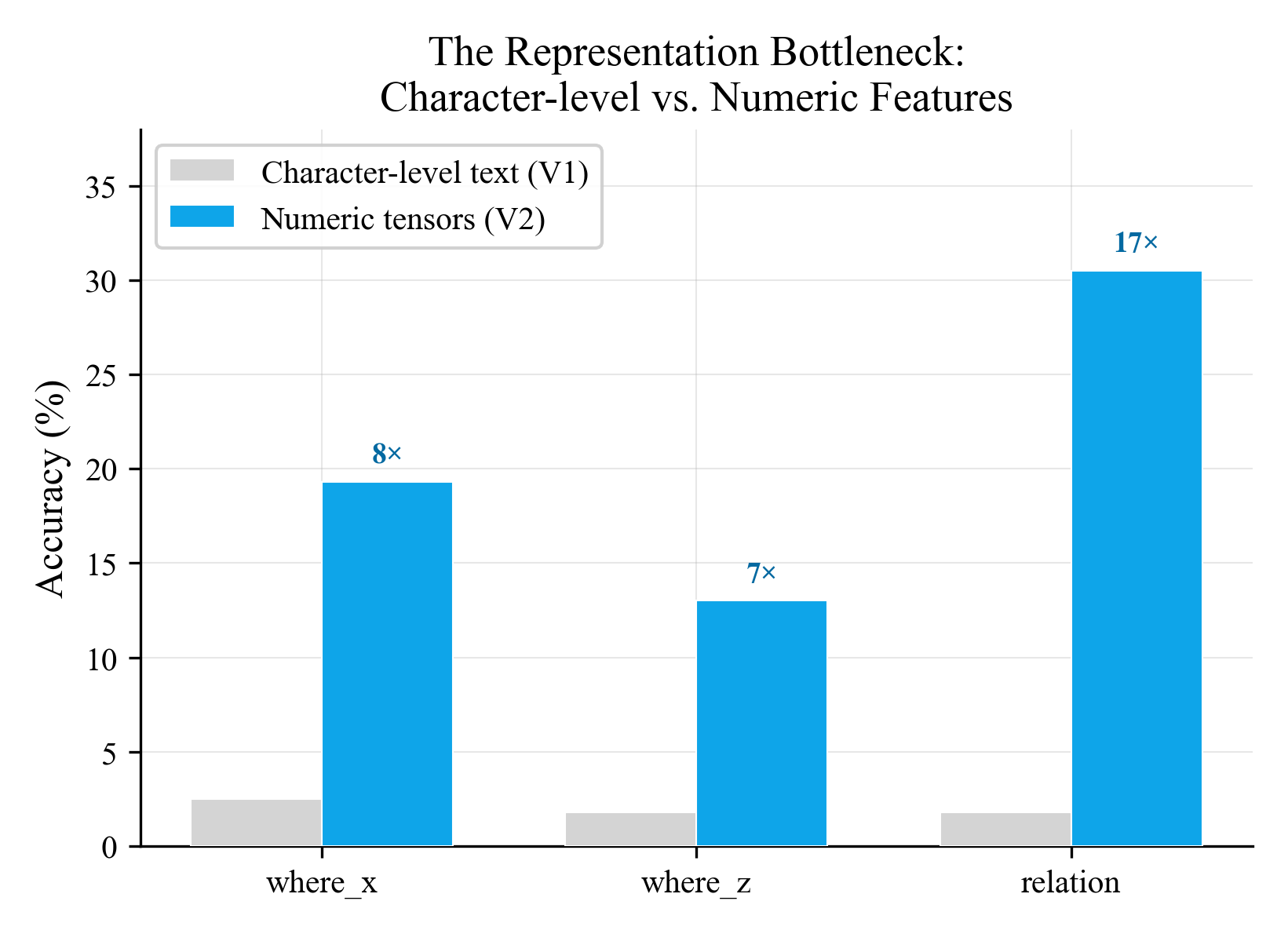
The chart shows the before and after. Where accuracy went from 2.5% to 19.3% (8x). Where on the other axis went from 1.8% to 13% (7x). Relation queries went from 1.8% to 30.5% (17x). The multipliers are printed on the bars because the improvement is that stark.
The extra bit that helped
On top of the numeric fix, I added auxiliary training losses. Instead of only training the model to answer the final question, I also trained it to predict object positions and visibility from its internal state at every step. This gave the model more signal about spatial structure during training and added another 1-3 points consistently.
Why this matters more than any architecture trick
This was the single biggest improvement across the entire series of experiments I ran (12 experiments total, spanning two weeks on A100 GPUs). No architecture change, no clever attention mechanism, no brain-inspired design came close to the impact of just fixing the input representation.
The models were capable of spatial reasoning the entire time. They just couldn't extract coordinate information from characters. It's a reminder that before you spend weeks tweaking your model, check whether the data format is the bottleneck. In my case, the answer was obviously yes, but it took running three failed experiments to see it.
One more thing: active sensing failed
After fixing the representation, I tried a model that could choose to "look around more" when it was uncertain. It had a learned halting mechanism: take 0-4 extra observation steps before answering. The idea was that uncertain questions should trigger more looking.
It collapsed immediately. The model learned to always take 0 extra steps and answer right away, regardless of difficulty. Even when extra steps were free (no penalty), the model refused to use them. Fixed-step experiments revealed why: extra views actually hurt coordinate reasoning because the movement disrupted the spatial reference frame, even though they helped counting (more viewpoints reveal more occluded objects).
More data is not always better. For precise spatial reasoning, a stable reference frame matters more than gathering more observations.